 Edge
Edge Chrome
Chrome Firefox
Firefox2025年1月20日特朗普上台,同一天DeepSeek发布R1模型,也是同一天梁文锋参加了专家、企业家和教科文卫体等领域代表座谈会(会议级别很高),并在会上发言。
2025年1月21日特朗普签署5000亿美元的“星际之门”计划,强化美国AI算力霸权。
春节期间DeepSeek凭借开源策略和低成本优势引爆全球市场,并迅速出圈,登顶中美应用商店下载榜,推动中国科技股开启估值修复行情。
2025年2月24日DeepSeek启动“开源周”,连续5天开放性能优化项目,通过算法改进降低算力需求,直指英伟达核心业务。
2025年2月26日英伟达收盘后要发布财报,从24号DeepSee计划启动“开源周”开始英伟达已连续下跌3天,市场担忧其业绩受DeepSeek技术冲击及全球算力需求萎缩双重打击,美股可能会剧烈波动。
DeepSeek给起的标题《中美AI博弈升级:DeepSeek开源突围引发美股震荡,英伟达财报成关键战场》
先持续跟踪后续
赞同来自: superwo
会,也不会,甚至会成为n卡的负担,因为商业模式变了。n卡在toB业务里会扩大优势;而deepseek帮其它卡厂家开辟的toC业务里,n卡会因为他们太过优秀的性能而无法覆盖到低端,只能主动让出这部分市场份额。打个比方,比如一套H800组成的服务器,可以服务200~500个并发,而AMD可以服务100~200个并发,但是价格只有H800的80%,那暂时不需要那么多并发的小企业肯定会考虑AMD的。芯片这...再解释一遍吧。在toB的业务场景里,算力越多越好,在数据交换上的花销越少越好,所以DeepSeek的优化对n卡是加强。
但是在toC的业务场景里,算力够用就行,性价比才是最大的考量。需要10块算力卡才能布置满血的DeepSeek,不是对算力的需求,而是对显存的需求。所以10卡的最低配置令人尴尬的点在于它的算力对于某些小型企业来说是过剩的,但是他的价格却降不下来。所以DeepSeek的优化对n卡没有作用,也不会对其它厂家的卡造成影响。


赞同来自: chuxingfei
你这前后矛盾,一句话里也能矛盾的思维,真的能挣钱吗?这是辩证法吧?deepseek对n卡的优化会加强n卡在toB市场的优势,但是会成为toC市场的劣势,这个很难理解吗?因为这两个市场的需求不一样啊,我后面甚至打了比方。
赞同来自: chuxingfei 、superwo 、明园
deepseek是在n卡上进行了优化部署,并且开源优化方案,这只会进一步提高n卡的护城河。会,也不会,甚至会成为n卡的负担,因为商业模式变了。n卡在toB业务里会扩大优势;而deepseek帮其它卡厂家开辟的toC业务里,n卡会因为他们太过优秀的性能而无法覆盖到低端,只能主动让出这部分市场份额。打个比方,比如一套H800组成的服务器,可以服务200~500个并发,而AMD可以服务100~200个并发,但是价格只有H800的80%,那暂时不需要那么多并发的小企业肯定会考虑AMD的。芯片这东西,卖得越多,研发成本就摊得越薄,然后它就有进一步的降价空间。我们国产的现阶段报价就能比n卡便宜35%以上,所以可以想象后续的价格战会有多大的降价空间。你也许会问n卡不也能降吗,它还真不能,因为它要考虑到不能让toB的客户有当冤大头的感觉,所以它不能降价,只能让老黄开启祖传的刀法,开一个新的产品来跟其它卡厂商争夺这部分市场。
n卡部署能效率提高,对其他卡,可不是什么好消息。
不,这个工作不需要DeepSeek去做。在此之前,算力卡+NVLINK+CUDA绑定在一起组成了护城河。他们需要解决算力卡大规模互联的效率问题,自家接口和大客户的模型的适配问题。但是现在,AMD/昇腾这些提供商可以先把大客户放在一边,只要在自家几张卡互联的服务器上把满血DeepSeek部署好就可以卖给那些需要AI辅助提升工作效率却不愿意暴露自家数据的中小型公司了。DeepSeek开源的这些技术,...你的意思是谁都能在底层优化程序执行?你确定其他的卡存在优化空间?其他卡是否存在巨大缺陷直接卡死了性能,谁来了也没招?
不是谁都能复制deepseek的。
但是n卡上已经优化过了,在n卡推广容易还是在其他卡推广容易?
赞同来自: chuxingfei 、zuzu2168
汇编更加底层,各个卡区别更大。deepseek在n卡上花了这么多心思,更加不可能换平台用其他家的卡,不然投入精力全部打水漂了?不,这个工作不需要DeepSeek去做。在此之前,算力卡+NVLINK+CUDA绑定在一起组成了护城河。他们需要解决算力卡大规模互联的效率问题,自家接口和大客户的模型的适配问题。但是现在,AMD/昇腾这些提供商可以先把大客户放在一边,只要在自家几张卡互联的服务器上把满血DeepSeek部署好就可以卖给那些需要AI辅助提升工作效率却不愿意暴露自家数据的中小型公司了。DeepSeek开源的这些技术,对其他厂家理解DeepSeek大模型,怎么优化自己的API接口让DeepSeek跑起来效率更高也是有帮助的。
实际上开源这些,对n卡来说,如虎添翼,指望deepseek把在n卡上投入的精力,再在华为的卡,或者其他家的卡上复制一遍,那怎么追赶openai?
目前来说,NVDA的卡会卖得更好,因为傻瓜式部署,买来就能用。但是等AMD/昇腾这些也适配好了,价格战可能就来了。
赞同来自: chuxingfei 、zuzu2168
韭菜的自我感动,要不得。首先,上来就给别人扣个"韭菜"的帽子的行为挺low的。论坛上想讨论问题就好好讨论问题。在市场上赚了点钱就高人一等的心态让其他也在这个市场揾食的人看了只会觉得无聊。
1.而现在一台H800服务器就能部署满血版DS
答:人工智能的核心在于算力,算法和数据。算法的改进只能缓解对算力的渴求,目前市面上想要满血版的ds,就要10张A100芯片,且并发量少。更何况在民族主义叙事下,ds已经超越了本该有的价值,甚至过于被神话了。例如潞晨科技官微发文宣布将暂停DeepSeek API服务,为什么?投入与收益完全不成比例。
2.DeepSeek开源的...
其次,你的阅读理解能力有点问题,或者你太以自己为中心,听不太进别人在讲什么。中小企业有使用AI提升效率的需求,而且也不渴求并发量。以前不想泄密就只能憋着,现在可以放心大胆的用。DeepSeek的出现帮助中小企业把算力、算法的问题都解决了,而数据部分恰恰是中小企业想独有,不想暴露的。而且你所谓的满血版DS需要10张A100这个认知也是错误的,对于要解决有无问题的中小企业来说,1万块的E5平台也不是不能用,10几万的AMD服务器或者多台苹果的MAC mini已经有能接受的响应速度。潞晨科技是要向外提供服务进行收费,而且所谓的收入与收益不成比例也被DeepSeek给怼回去了。
我自己是做嵌入式开发的,我很清楚DeepSeek讲的汇编指的是什么。但是你并没有看懂我说的。他使用汇编表明了上层CUDA封装不是,至少不完全是NVDA算力卡的护城河。
更名了jxjx - 分级基金好
韭菜的自我感动,要不得。
1.而现在一台H800服务器就能部署满血版DS
答:人工智能的核心在于算力,算法和数据。算法的改进只能缓解对算力的渴求,目前市面上想要满血版的ds,就要10张A100芯片,且并发量少。更何况在民族主义叙事下,ds已经超越了本该有的价值,甚至过于被神话了。例如潞晨科技官微发文宣布将暂停DeepSeek API服务,为什么?投入与收益完全不成比例。
2.DeepSeek开源的...
- 潞晨科技亏钱关dp什么事,再说了潞晨在AI里能排多少?一家注册资本100万的公司。
2.这个汇编语言不是英伟达还能是谁的?单就语言来说,c/c++,还是汇编更接近底层?越底层的语言性能越好,当然使用起来也是越难,用汇编难度比用c/c++高出几个数量级。
韭菜的自我感动,要不得。根据公开信息,DeepSeek 在技术实现中确实涉及通过汇编语言优化底层硬件性能,但其使用的汇编语言并非英伟达(NVDA)产品专用的语言,而是针对 英伟达 GPU 架构的低级指令集(如 PTX 或 SASS)进行的优化。以下是综合分析:
1.而现在一台H800服务器就能部署满血版DS
答:人工智能的核心在于算力,算法和数据。算法的改进只能缓解对算力的渴求,目前市面上想要满血版的ds,就要10张A100芯片,且并发量少。更何况在民族主义叙事下,ds已经超越了本该有的价值,甚至过于被神话了。例如潞晨科技官微发文宣布将暂停DeepSeek API服务,为什么?投入与收益完全不成比例。
2.DeepSeek开源的...
1. 技术背景与绕过 CUDA 的逻辑
- CUDA 是英伟达为 GPU 计算设计的并行计算平台和编程模型,通常需依赖其上层封装接口。而 DeepSeek 通过直接操作 GPU 底层指令集(如汇编级别的优化),绕过了 CUDA 的抽象层,从而提升计算效率和成本控制。- 这种优化方式类似于直接编写针对特定硬件架构的机器码,能够更高效地利用 GPU 资源,减少因 CUDA 中间层带来的性能损耗。
2. 汇编语言的具体类型
- 英伟达 GPU 的底层指令集主要包括 PTX(Parallel Thread Execution) 和 SASS(Shader Assembly)。前者是虚拟指令集,可跨代兼容;后者是硬件直接执行的二进制指令,与具体 GPU 架构(如 Ampere、Hopper)强相关。- DeepSeek 的技术文档提到其优化涉及“解码内核、通信库、GEMM 库”等底层组件,结合其使用英伟达 A100 GPU 的硬件配置(如网页6所述),推测其汇编优化可能基于 SASS 或 PTX 指令集,而非通用 CPU 汇编语言。
3. 技术争议与英伟达的回应
- 部分媒体称此举可能削弱英伟达 CUDA 生态的护城河,但实际影响仍存争议。例如:- DeepSeek 的训练仍依赖英伟达 A100 GPU,且其优化技术并未完全脱离英伟达硬件架构。
- 英伟达官方对 DeepSeek 的技术进步表示认可,认为其展示了如何利用“完全符合出口管制的计算资源”实现创新。
- 技术文档(网页8)也澄清,DeepSeek 并未完全绕过 CUDA,而是在 混合精度训练、内核优化 等方面结合了 CUDA 生态与自主优化策略。
4. 实际效果与行业意义
- 通过底层优化,DeepSeek 在训练成本上显著降低(例如 Janus-Pro 模型仅用 256 块 A100 GPU 训练两周),但其性能优势主要集中在特定任务(如多模态生成),通用算力需求仍依赖英伟达硬件。- 这种技术路径更多是 “软硬件协同优化” 的体现,而非彻底替代 CUDA。长远来看,可能推动英伟达进一步开放底层接口或优化工具链。
结论
DeepSeek 使用的汇编语言是 针对英伟达 GPU 架构的底层指令集(如 SASS/PTX),通过直接操作硬件资源提升效率。这种技术并未脱离英伟达的硬件体系,但展示了算法与硬件协同优化的可能性,对 CUDA 生态的长期影响仍需观察。DeepSeek不需要做到非常优秀(其实它很优秀),它只要做到够用就行了。在它出现之前,主流声音就是more and more,算力越大越好,大家巴不得堆万卡集群甚至10万卡集群,Altman说过大模型训练一次要数千万美刀。所以我们看到企鹅向NVDA下订单都是几十亿美刀,AI成了事实上的寡头垄断游戏。想超过我,直接不给你最新的芯片;你有新的创意和私密数据但是需要算力做辅助?乖乖用我的API,给我...汇编更加底层,各个卡区别更大。deepseek在n卡上花了这么多心思,更加不可能换平台用其他家的卡,不然投入精力全部打水漂了?
实际上开源这些,对n卡来说,如虎添翼,指望deepseek把在n卡上投入的精力,再在华为的卡,或者其他家的卡上复制一遍,那怎么追赶openai?
DeepSeek不需要做到非常优秀(其实它很优秀),它只要做到够用就行了。在它出现之前,主流声音就是more and more,算力越大越好,大家巴不得堆万卡集群甚至10万卡集群,Altman说过大模型训练一次要数千万美刀。所以我们看到企鹅向NVDA下订单都是几十亿美刀,AI成了事实上的寡头垄断游戏。韭菜的自我感动,要不得。
想超过我,直接不给你最新的芯片;你有新的创意和私密数据但是需要算力做辅助?乖乖用我的API,给我...
1.而现在一台H800服务器就能部署满血版DS
答:人工智能的核心在于算力,算法和数据。算法的改进只能缓解对算力的渴求,目前市面上想要满血版的ds,就要10张A100芯片,且并发量少。更何况在民族主义叙事下,ds已经超越了本该有的价值,甚至过于被神话了。例如潞晨科技官微发文宣布将暂停DeepSeek API服务,为什么?投入与收益完全不成比例。
2.DeepSeek开源的技术细节里使用了汇编,绕过了上层CUDA的封装,有人说它不还是依赖NVDA吗?
答:新闻告诉你前半句,没告诉你的后半句是,他用的汇编语言,是英伟达另一种语言罢了。
其他就不一一反驳了,理智才能在投资里活下来
赞同来自: OCGP 、chuxingfei 、superwo
想超过我,直接不给你最新的芯片;你有新的创意和私密数据但是需要算力做辅助?乖乖用我的API,给我交着钱还用你的数据来喂我的大模型。
所以当DeepSeek出现后,它都不用做任何动作,甚至在短期内它还能促进NVDA卡的销售,但是老美试图垄断的意图就被打破了。AI原本应该是铲子的角色,利用AI辅助设计/生产的才是挖金子的人。可是老美试图让所有挖金子的人都给它们打工,卖铲子的人要拿最大头的利润。而现在一台H800服务器就能部署满血版DS,大多数中小型企业都能负担得起,它们都用得起了,也不用拿自己的私密数据去喂那些寡头的大模型了。
DeepSeek开源的技术细节里使用了汇编,绕过了上层CUDA的封装,有人说它不还是依赖NVDA吗?并不是,能用汇编说明DeepSeek的这群小伙子们是真的理解自己的工作内容,也吃透了自己的算法需要怎么去调度硬件来达到更好的效果。只要假以时日,他们完全有能力移植到别的算力平台上,所以苏妈才笑得那么开心,是的,短期内老黄的卡会卖得更好更多,但是随着其它平台移植成功,大家会有更多的选择,NVDA不再是唯一的那个。
最可乐的是,老美AI行业寡头们被打得有苦难言,而DeepSeek却一脸无辜的说:啊,我们只是在开源社区受益良多,现在轮到我们来回馈社区了。
赞同来自: superwo
https://github.com/deepseek-ai/FlashMLA
day 2
https://github.com/deepseek-ai/DeepEP
day 3
https://github.com/deepseek-ai/DeepGEMM
day 4
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
day 5
https://github.com/deepseek-ai/3FS
DeepSeek开源周成果汇总
美国的OpenAI也就图一乐,真开源还得看DeepSeek
楼主:对潞晨科技的做法及尤洋的说法如何评价?潞晨科技尤洋这人纯纯小丑,他自家的公司搞卖TOKEN的模式亏不起钱了就臆想DeepSeek肯定也亏不起
结果:1、DeepSeek公布了自己的理论利润率,离亏钱还远得很
2、但凡读过梁文峰的两篇访谈都知道DeepSeek就不是冲着卖TOKEN赚钱去的,是为了探索更基础更底层的架构,目前的DeepSeek API收费模式只是为了保本罢了
上周DeepSeek 开源周公布的一系列成果,甚至到了优化GPU底层代码的地步,连CUDA都绕开了,把英伟达本来该干却没干的活都给干了,这是一种纯粹的开源精神
DS开源的这些东西,压根就不是给一般个人用户准备的,用来尽可能榨取出硬件的潜力,属于最上游的部份了
superwo - 专长、利他、真诚、持续
赞同来自: chuxingfei
但是部署ds满血版 人家配置写了 最低配置要英伟达的什么级别的独立显卡..只能说是刷了一下存在感 真要对英伟达造成实质上的冲击 还是得造出同样性能的芯片.在这里的什么级别英伟达芯片,显然是将英伟达当作计量单位,谁也无法否认英伟达是最强的,我表述的是英伟达在逐步丧失垄断地位
腾讯科技:读懂DeepSeek开源周:一场技术普惠的嘉年华,极限提升大模型效率https://mp.weixin.qq.com/s/FsB5ZFt1jbbNMASZpwNtBQ楼主:对潞晨科技的做法及尤洋的说法如何评价?
superwo - 专长、利他、真诚、持续
https://mp.weixin.qq.com/s/FsB5ZFt1jbbNMASZpwNtBQ

赞同来自: 阳光下生命 、地理科代表 、happysam2018 、superwo
但听报道说deepseek绕开了英伟达CUDA的50%。这个才是给了其他GPU崛起的机会。
superwo - 专长、利他、真诚、持续
赞同来自: happysam2018 、hao8000
superwo - 专长、利他、真诚、持续
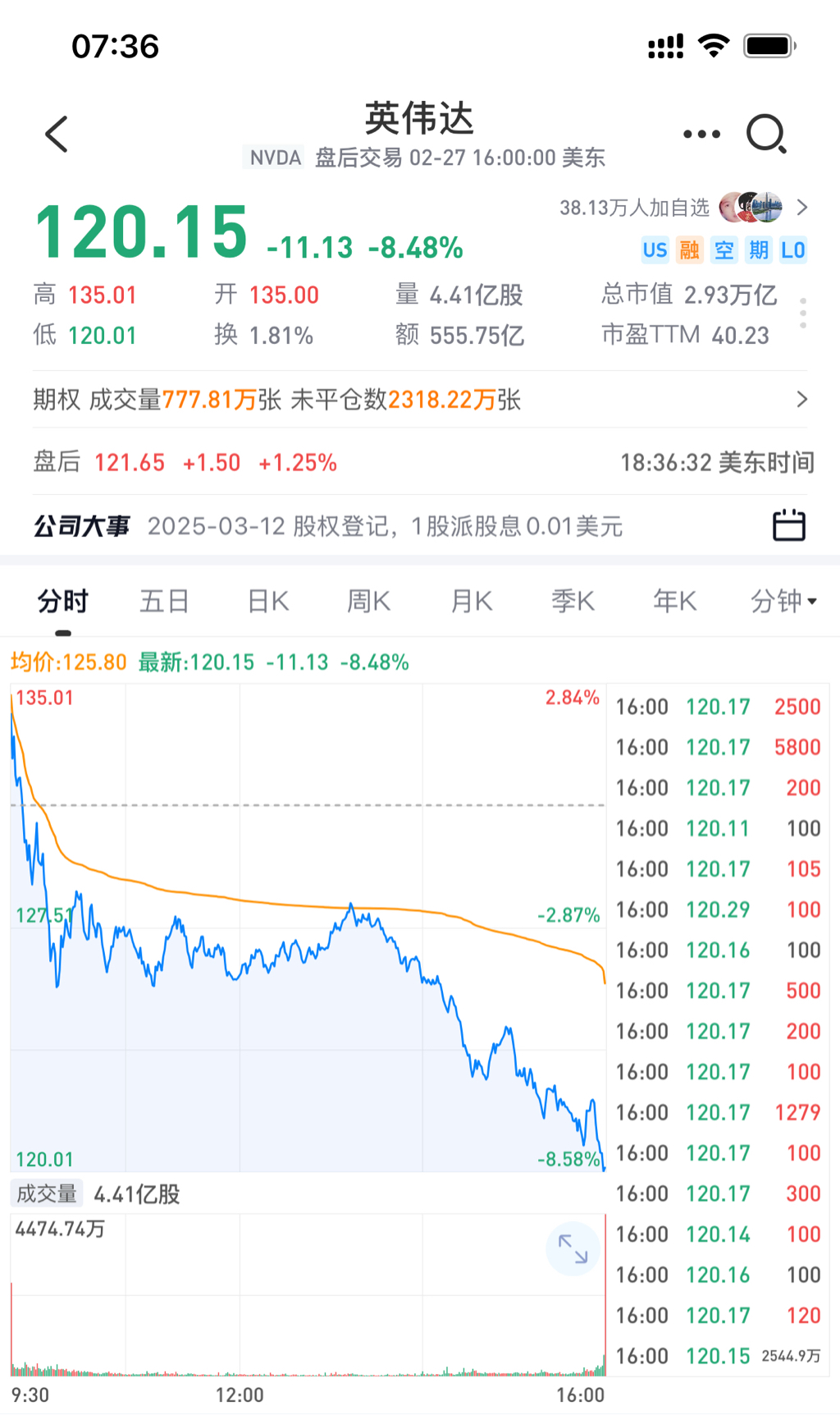
英伟达在一众认为业绩符合预期的情况下暴跌8.5%,英伟达AI芯片领域还是最强的,
但垄断神话被Deepseek戳破了,
垄断的时候可以给你科技公司估值,
不垄断只能给制造公司估值。
superwo - 专长、利他、真诚、持续
赞同来自: 小猫50128015 、happus 、阿戒1899 、coolchan 、地理科代表 、 、 、更多 »
1.美国因为手里没钱并且收不上来税,富豪的税他收不到,贸易战其实是变相的给普通民众加税(关税如果是为了制造业回流,应该先等回流之后再加关税),退群也是为了缩减开支,马斯克效率部门降本增效也是为了缩减开支,让盟友们自己承担军费也是缩减开支。
2.美国现在国债利率很高,导致目前很多长期贷款到期后,重新发行的长期国债利息太高,所以耶伦在的时候大幅增加短期国债的规模(因为美国政府的国债发行后不允许提前结清赎回),就是想等以后利率降低后,再将短期国债置换为低息长期国债,以降低成本。
 京公网安备 11010802031449号
京公网安备 11010802031449号